
TL;DR
- QUERY is now a real HTTP method. RFC 10008 is published on the IETF Standards Track - no longer a decade-old draft.
- It's a request with a body that is safe, idempotent, and cacheable - the gap between GET and POST.
- It fixes a problem every API team knows: using POST for reads just to avoid giant URLs or to keep filters out of logs.
- A new verb (not "GET with a body") is a deliberate choice - it makes support explicit and debuggable.
- Our read: browsers and frameworks will move fast; enterprise proxies, WAFs, and gateways will not. Expect a multi-year gap.
For years, HTTP felt done. GET, POST, PUT, PATCH, DELETE - you learned them once and moved on. Then RFC 10008 landed and added a genuinely new verb: QUERY. The developer reaction has been a mix of "finally" and "I'll believe it when my proxy allows it." Both are fair. Let's unpack what it really does, using the spec itself as the source.
What QUERY actually is
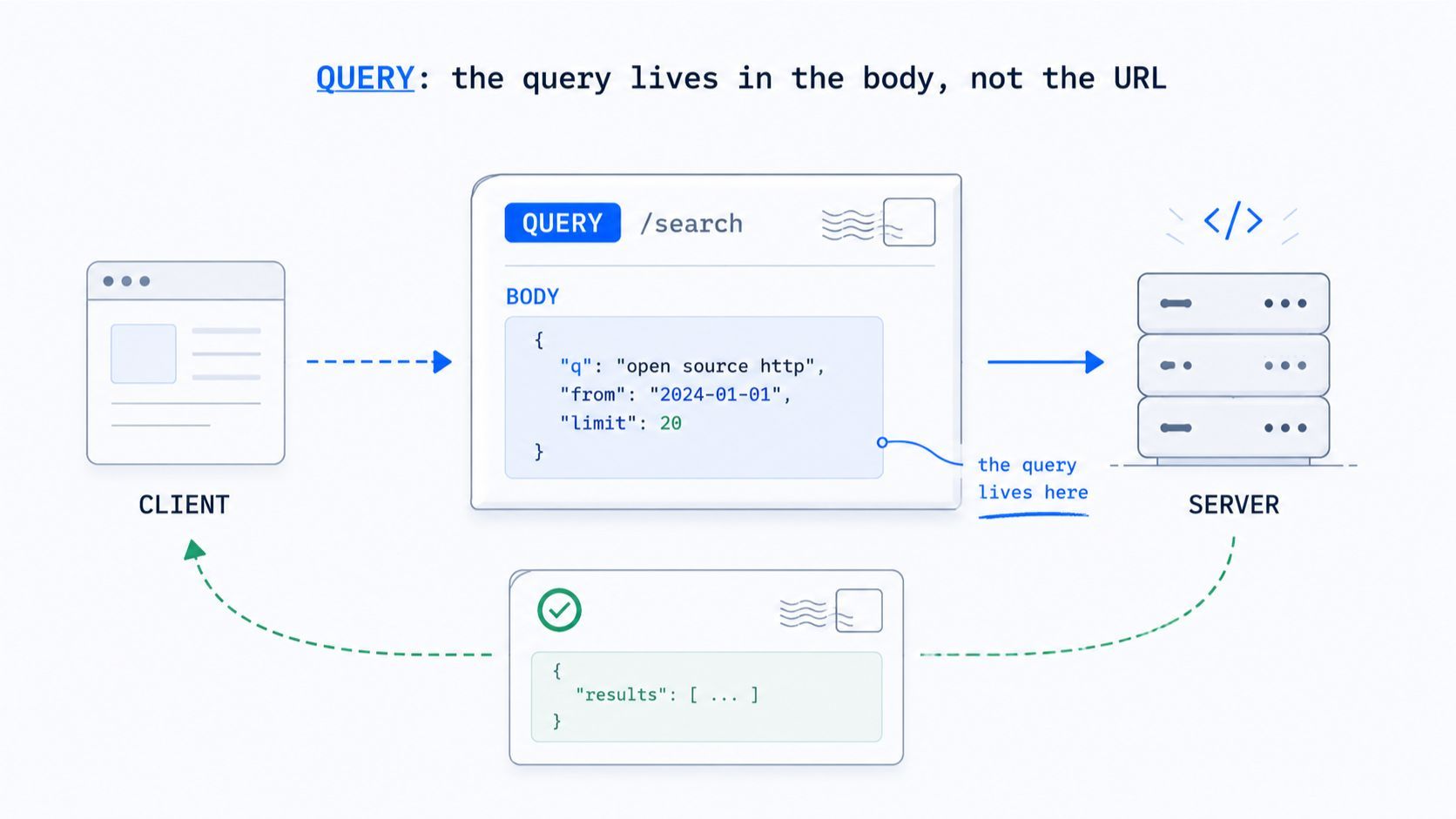
Straight from the RFC: a QUERY request "requests that the request target process the enclosed content in a safe and idempotent manner and then respond with the result of that processing." In simple words; you send a query in the request body, the server runs it, and hands back the result. It reads data. It does not change it.
Three properties do the heavy lifting, and they're the whole point:
- Safe - it's a read. It isn't supposed to change server state.
- Idempotent - repeating it is fine. The spec notes QUERY requests "can be automatically repeated or restarted without concern for partial state changes."
- Cacheable - responses can be cached, with the cache key built from the request body, not just the URL.
QUERY /feed HTTP/1.1 Host: example.org Content-Type: application/x-www-form-urlencoded q=foo&limit=10&sort=-published
One sharp detail worth knowing: servers MUST fail the request if there's no Content-Type. The body is the query, so its format isn't optional.
QUERY vs GET vs POST, per the spec

The RFC includes a comparison table.
Read the QUERY column top to bottom and the design intent is obvious: take POST's body and give it GET's guarantees.
The real problem it solves
The RFC is unusually candid about why this exists. Cramming query data into a URL breaks down for four concrete reasons it lists: URL length limits you can't predict across systems (it notes the recommended floor is only ~8,000 octets), inefficient encoding, URLs getting logged and bookmarked, and every filter combo becoming a "distinct resource."
So teams reached for POST instead. And the spec names that workaround directly: with a POST, "it is not readily apparent, without specific knowledge of the resource and server, that a safe, idempotent query is being performed." You lose caching and safe retries, and you muddy the meaning of POST.
Grounded in practice: This isn't theoretical. In developer discussions on the RFC, engineers at banks and fintechs repeatedly said the same thing, they use POST for the majority of what are really reads, because their security teams don't want query parameters showing up in URLs and logs. The RFC's own Security Considerations section validates exactly this: "where the query contains sensitive information, the potential for logging of the URI might motivate the use of QUERY over GET." QUERY finally gives that pattern a correct, standard home.
Why a new verb, and not just "GET with a body"?
This was the top question in the community and the best answer, echoed by the spec's spirit, is about failure modes. A GET body has "no defined semantics." Some servers read it, many proxies silently drop it, some reject it. So a GET-with-body request can fail invisibly, somewhere in the middle of your infrastructure, with nothing telling you why.
A distinct method removes the ambiguity. A server that doesn't understand QUERY returns a clear "method not allowed." You learn instantly, instead of debugging a body that vanished three hops upstream. Explicit beats implicit especially across networks you don't control.
Our analysis: what QUERY does not fix
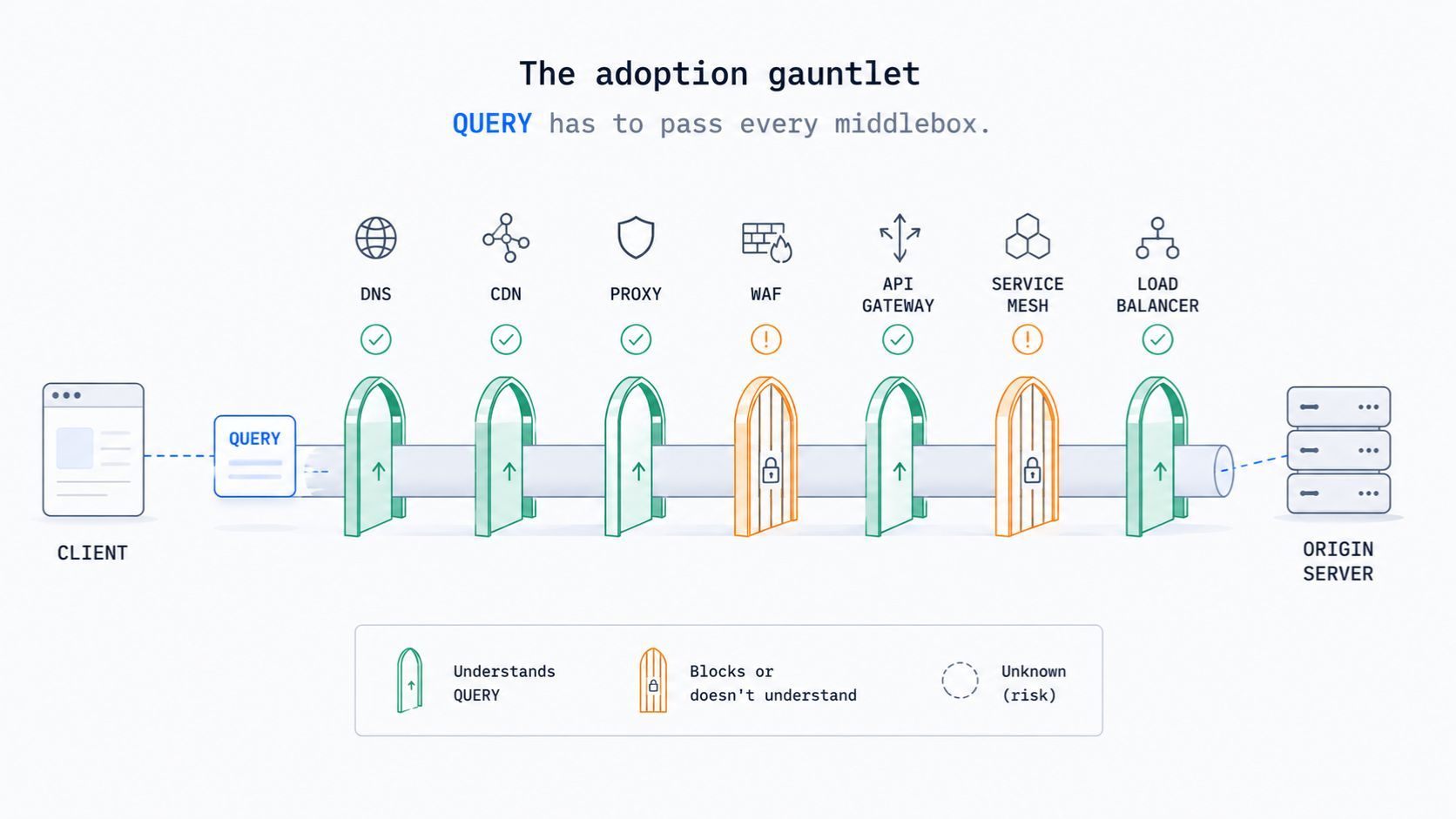
Here's where we'll add our own read, clearly labeled as deduction rather than spec.
1. Adoption is an infrastructure problem, not a browser problem.
Clients can send custom methods today via fetch. The blocker is everything in between reverse proxies, WAFs, API gateways, CDNs, and corporate TLS-inspection boxes that terminate your traffic and only allow "known" methods. Our deduction: expect client and framework support within roughly a year, and enterprise middlebox support to lag by years. The pattern rhymes with how long PATCH took to be safe everywhere.
2. TLS won't save you in the enterprise.
A common assumption is "HTTPS hides the method, so proxies won't care." True on the open internet. False in many enterprises, where MITM/TLS-inspection appliances decrypt, inspect, and re-issue requests, and will drop an unknown verb. Our prediction: teams will bridge the gap with X-HTTP-Method-Override: QUERY over POST for a long while.
3. "In the body" is not the same as "private."
QUERY keeps data out of the URL, which helps with logs and bookmarks. But the RFC adds a caution people will miss: if a server mints a result URI (Location/Content-Location), that URI "SHOULD be chosen such that it does not include any sensitive portions of the original" query. Our takeaway: QUERY reduces one class of leakage; it doesn't make a query secret. Design accordingly.
Who benefits first (our prediction)
Based on the spec and where the pain is concentrated today, we expect the earliest wins here:
- Search and filter endpoints with big, structured queries that don't fit cleanly in a URL.
- GraphQL-style and analytics APIs that were forced onto POST purely because their queries are large.
- Fintech, banking, and health teams who want reads out of URLs and logs, with a correct semantic label.
- AI tooling and agents. One point raised in the discussion is genuinely forward-looking: cleanly separating query from mutation matters for agent safety and dry-runs. A verb that says "this only reads" is useful when a model, not a human, is deciding whether to call it.
What to do now
You don't need to rewrite anything this quarter. But two moves are worth making. First, if you control a service end to end (internal APIs, service-to-service traffic), QUERY is a reasonable place to pilot. Second and this is the bigger one design your API layer so the method is easy to swap later. Keep query logic separate from transport, so moving a read from POST to QUERY is a config change, not a refactor.
That "build it so tomorrow's standard is a small change, not a big one" mindset is most of good engineering. It's also, honestly, most of what we do.
Designing or modernizing an API and unsure where QUERY fits?
Getting method semantics right - clean reads, safe retries, cache keys, sane fallbacks for old infrastructure is exactly the kind of detail that saves a rewrite later.
→ Book a 30-min call · See the work
Frequently Asked Questions
What is the HTTP QUERY method?
QUERY (RFC 10008) asks a server to run a query and return a result, with the query held in the request body. It's like POST because the body carries the query, but unlike POST it's explicitly safe and idempotent, so it can be cached and safely retried.
How is QUERY different from GET and POST?
GET puts parameters in the URL and its body has no defined meaning. POST has a body but isn't guaranteed safe or idempotent, so it isn't cacheable as a read. QUERY gives you a body that is safe, idempotent, and cacheable built for complex reads.
Is RFC 10008 approved or just a draft?
Approved and published. It's an IETF Internet Standards Track document, approved by the IESG in 2026 after years as a draft. Real-world support across browsers, proxies, and gateways will still roll out gradually.
Why not just allow a body on GET?
A GET body has no defined semantics and many proxies silently drop it, causing confusing failures. A distinct QUERY method makes support explicit: unsupported servers return a clear error instead of quietly discarding your data.
Should I use QUERY in production now?
For services you control end to end, yes, you can pilot it. For public or enterprise traffic, expect middleboxes and gateways to lag, many teams will keep using POST or X-HTTP-Method-Override until infrastructure catches up. Design so switching later is cheap.
Primary source: RFC 10008 — The HTTP QUERY Method (IETF, 2026). All quoted properties (safe, idempotent, cacheable, Content-Type requirement, comparison table, and Security Considerations) are drawn directly from the specification. Practitioner patterns referenced are from public developer discussion of the RFC; predictions on adoption timelines are TechOrigins' own analysis, labeled as such.